Import Job Task
Note: The Import tool imports structured data from an RDBMS to HDFS. Each row from a table is represented as a separate record in HDFS. Records can be stored as text files (one record per line), or in binary representation as Avro or SequenceFiles.
This page contains these elements:
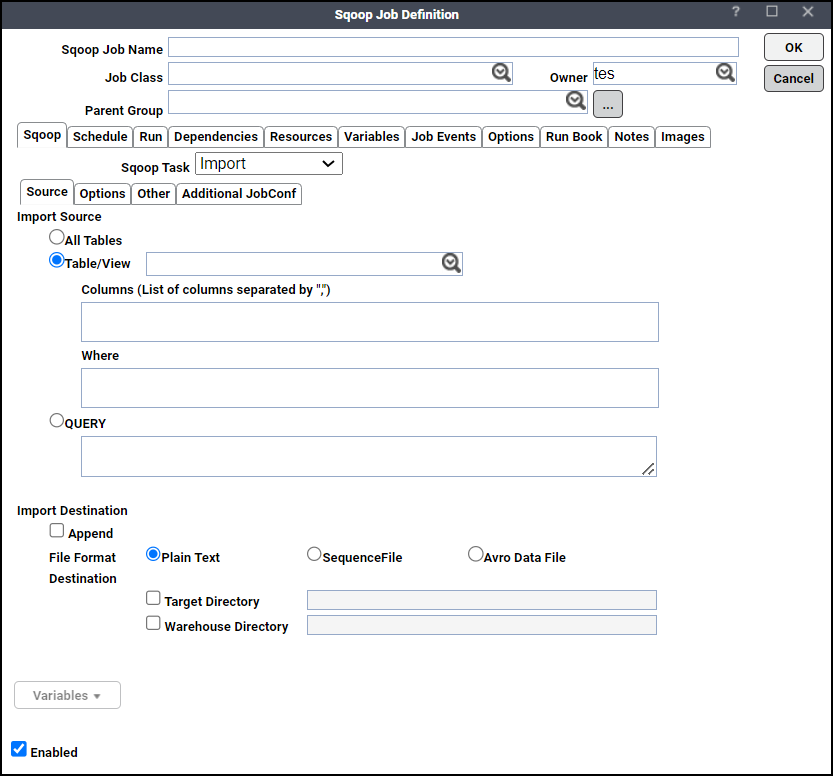
Source Tab
This tab contains these elements:
-
All Tables – This tool imports a set of tables from an RDBMS to HDFS. Data from each table is stored in a separate directory in HDFS.
For the import-all-tables tool to be useful, meet these conditions:
Each table has a single-column primary key.
You import all columns of each table.
You do not intend to use non-default splitting column, nor impose any conditions via a WHERE clause.
-
Table/View – Sqoop typically imports data in a table-centric fashion. This field can also identify a view or other table-like entity in a database. By default, all columns within a table are selected for import. You can choose a subset of columns and control their ordering by using the selected Column grid you can control which rows are imported by adding a SQL WHERE clause to the import statement.
-
Query – Sqoop can also import the result set of an arbitrary SQL query.
When importing a free-form query, you should specify a destination directory on the Destination tab.
The facility of using free-form query in the current version of Sqoop is limited to simple queries where there are no ambiguous projections and no OR conditions in the WHERE clause. Use of complex queries such as queries that have sub-queries or joins leading to ambiguous projections can lead to unexpected results.
-
Append – By default, imports go to a new target location. If the destination directory already exists in HDFS, Sqoop will refuse to import and overwrite that directory's contents. If you check this checkbox, Sqoop will import data to a temporary directory and then rename the files into the normal target directory in a manner that does not conflict with existing filenames in that directory.
-
File Formats – Sqoop supports these file formats:
Plain Text – Delimited text is the default import format. This argument will write string-based representations of each record to the output files, with delimiter characters between individual columns and rows. Delimited text is appropriate for most non-binary data types. It also readily supports further manipulation by other tools, such as Hive.
Sequence File – This is binary format that store individual records in custom record-specific data types. These data types are manifested as Java classes. Sqoop will automatically generate these data types for you. This format supports exact storage of all data in binary representations, and is appropriate for storing binary data. Reading from SequenceFiles is higher-performance than reading from text files, as records do not need to be parsed.
Avro File – Avro data files are a compact, efficient binary format that provides interoperability with applications written in other programming languages. Avro also supports versioning, so that when, e.g., columns are added or removed from a table, previously imported data files can be processed along with new ones.
-
Destination directory can be specified in 2 ways:
Target Directory – HDFS destination directory. This field is mandatory when importing a free-form query OR
Warehouse Directory – You can adjust the parent directory of the import with this location set. By default, Sqoop will import a table named foo to a directory named foo inside your home directory in HDFS. For example, if your username is someuser, then the import tool will write to /user/someuser/foo/(files). You can adjust the parent directory of the import by using this field.
Options Tab
This tab contains these elements:
Note: You can click Variables to insert a predefined variable into a selected field on this tab.
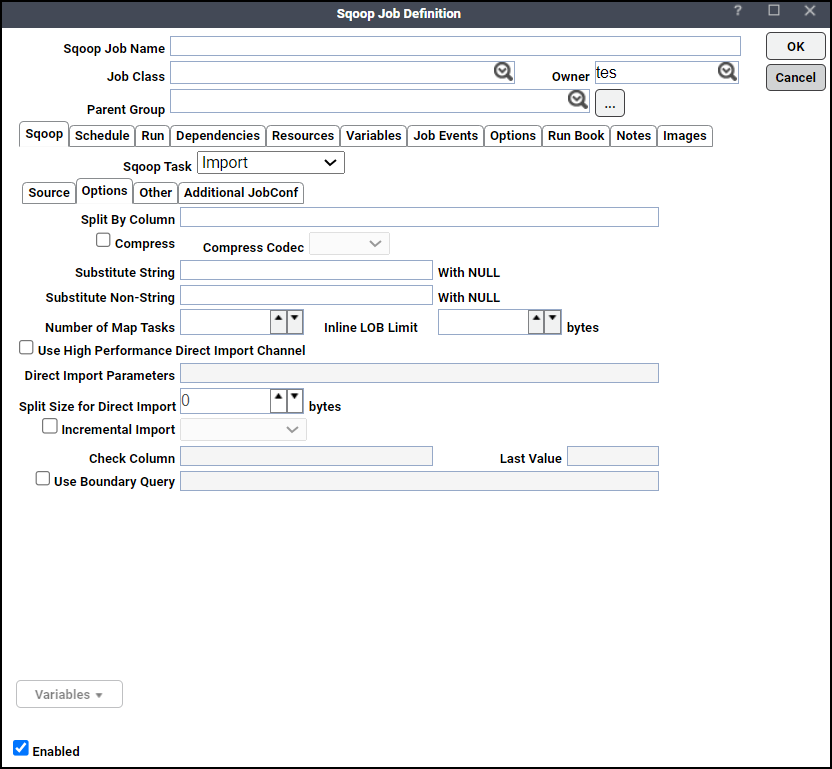
-
Split By Column – Column of the table used to split work units. If you want to import the results of a query in parallel, then each map task will need to execute a copy of the query, with results partitioned by bounding conditions inferred by Sqoop. Your query should include the token $CONDITIONS which each Sqoop process will replace with a unique condition expression. You should also choose a splitting column with this field.
Since result of a free form query does not have a primary key it is mandatory to provide a split by column while importing the data using free form query.
This field is disabled for Import of all tables from database.
If the actual values for the primary key are not uniformly distributed across its range, then this can result in unbalanced tasks. You should explicitly choose a different column using this field. Sqoop cannot currently split on multi-column indices. If your table has no index column, or has a multi-column key, then you should also manually choose a splitting column.
-
Compress – Enable compression. By default, data is not compressed. You can compress your data by using the deflate (gzip) algorithm with this checkbox checked.
-
Compression Codec – User can specify any Hadoop compression codec using field. This applies all file formats supported by sqoop.
-
Substitute Null with – The value you want to substitute for null.
-
For String –The string to be written for a null value for string columns.
-
For Non-String –The string to be written for a null value for non-string columns. If not specified, then the string "null" will be used.
-
-
Number of Mappers – Number of Map tasks to import in parallel. Sqoop imports data in parallel from most database sources. You can specify the number of map tasks (parallel processes) to use to perform the import by using this field. It takes an integer value which corresponds to the degree of parallelism to employ. By default, four tasks are used. Some databases may see improved performance by increasing this value to 8 or 16.
Do not increase the degree of parallelism greater than that available within your MapReduce cluster; tasks will run serially and will likely increase the amount of time required to perform the import. Likewise, do not increase the degree of parallelism higher than that which your database can reasonably support. Connecting 100 concurrent clients to your database may increase the load on the database server to a point where performance suffers as a result.
-
Inline LOB Limit – Sqoop handles large objects (BLOB and CLOB columns) in particular ways. If this data is truly large, then these columns should not be fully materialized in memory for manipulation, as most columns are. Instead, their data is handled in a streaming fashion. Large objects can be stored inline with the rest of the data, in which case they are fully materialized in memory on every access, or they can be stored in a secondary storage file linked to the primary data storage. By default, large objects less than 16 MB in size are stored inline with the rest of the data. At a larger size, they are stored in files in the _lobs subdirectory of the import target directory. These files are stored in a separate format optimized for large record storage, which can accommodate records of up to 2^63 bytes each. The size at which lobs spill into separate files is controlled by the --inline-lob-limit argument, which takes a parameter specifying the largest lob size to keep inline, in bytes. If you set the inline LOB limit to 0, all large objects will be placed in external storage. For high performance direct imports this field will be disabled and will not be passed over to sqoop tool.
-
Use High Performance Direct Import channel – Uses direct import fast path if selected. By default, the import process will use JDBC which provides a reasonable cross-vendor import channel. Some databases can perform imports in a more high-performance fashion by using database-specific data movement tools. For example, MySQL provides the mysqldump tool which can export data from MySQL to other systems very quickly. You are specifying that Sqoop should attempt the direct import channel. This channel may be higher performance than using JDBC. Currently, direct mode does not support imports of large object columns.
Sqoop's direct mode does not support imports of BLOB, CLOB, or LONGVARBINARY columns. Use JDBC-based imports for these columns. It is user's responsibility to not choose the direct mode of import if these kinds of columns are involved in import.
-
Split size for direct Import – Split the input stream every n bytes when importing in direct mode. When importing from PostgreSQL in conjunction with direct mode, you can split the import into separate files after individual files reach a certain size. This size limit is controlled with this field.
-
Incremental Import – Sqoop provides an incremental import mode which can be used to retrieve only rows newer than some previously-imported set of rows.
There are two modes:
-
Append – You should specify append mode when importing a table where new rows are continually being added with increasing row id values.
-
Last modified – You should use this when rows of the source table may be updated, and each such update will set the value of a last-modified column to the current timestamp. Rows where the check column holds a timestamp more recent than the timestamp specified with last value field are imported.
-
-
Check column – Specifies the column to be examined when determining which rows to import during incremental import.
-
Last Value – Specifies the maximum value of the check column from the previous import during incremental import.
-
Use boundary Query – Boundary query to use for creating splits. By default sqoop will use query choose min (<split-by>), max (<split-by>) from <table name> to find out boundaries for creating splits. In some cases this query is not the most optimal so you can specify any arbitrary query returning two numeric columns using boundary-query.
Other Tab
This tab contains these elements:
Note: You can click Variables to insert a predefined variable into a selected field on this tab.
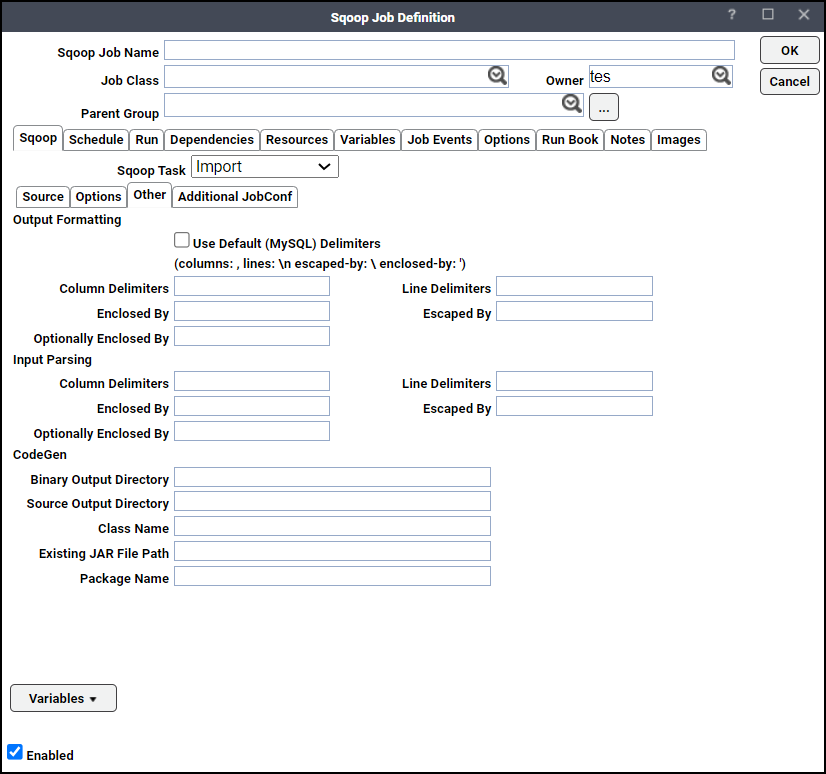
-
Use Default Delimiters – Choose this option to use MySQL's default delimiter set.
Example: fields: , lines: \n escaped-by: \ optionally-enclosed-by: '
-
Column Delimiters – Sets the field separator character.
-
Line Delimiters – Sets the end-of-line character.
-
Enclosed By – Sets a required field enclosing character.
-
Escaped By – Sets the escape character.
-
Optionally Enclosed By – Sets a field enclosing character.
In the CodeGen section, enter:
-
Column Delimiters – Sets the input field separator.
-
Line Delimiters – Sets the input end-of-line character.
-
Enclosed By – Sets a required field encloser.
-
Escaped By – Sets the input escape character.
-
Optionally Enclosed By – Sets a field enclosing character.
In the CodeGen section, enter:
-
Binary Output Directory – Output directory for compiled objects.
-
Class Name – Sets the generated class name. This overrides package-name.
-
Source Output Directory – Output directory for generated code.
-
Existing Jar File Path – Enter the path of the jar to reuse for import. This disables code generation.
-
Package Name – Put auto-generated classes in this package.